Contexte et enjeu
La recherche d'offres ciblées et la collecte des coordonnées des recruteurs sont souvent manuelles et chronophages. L'objectif de ce projet R&D réalisé durant la formation était d'automatiser 95% du processus : de la veille des offres jusqu'à l'enrichissement des contacts.
Ce pipeline permet de transformer une tâche récurrente et peu scalable en un flux reproductible, traçable et actionnable.
Données & méthodologie (Le Workflow)
Le pipeline s'articule autour de Make (orchestrateur), Apify (collecte web) et Apollo (enrichissement). Les données sont conservées et pilotées via Google Sheets pour faciliter le suivi.
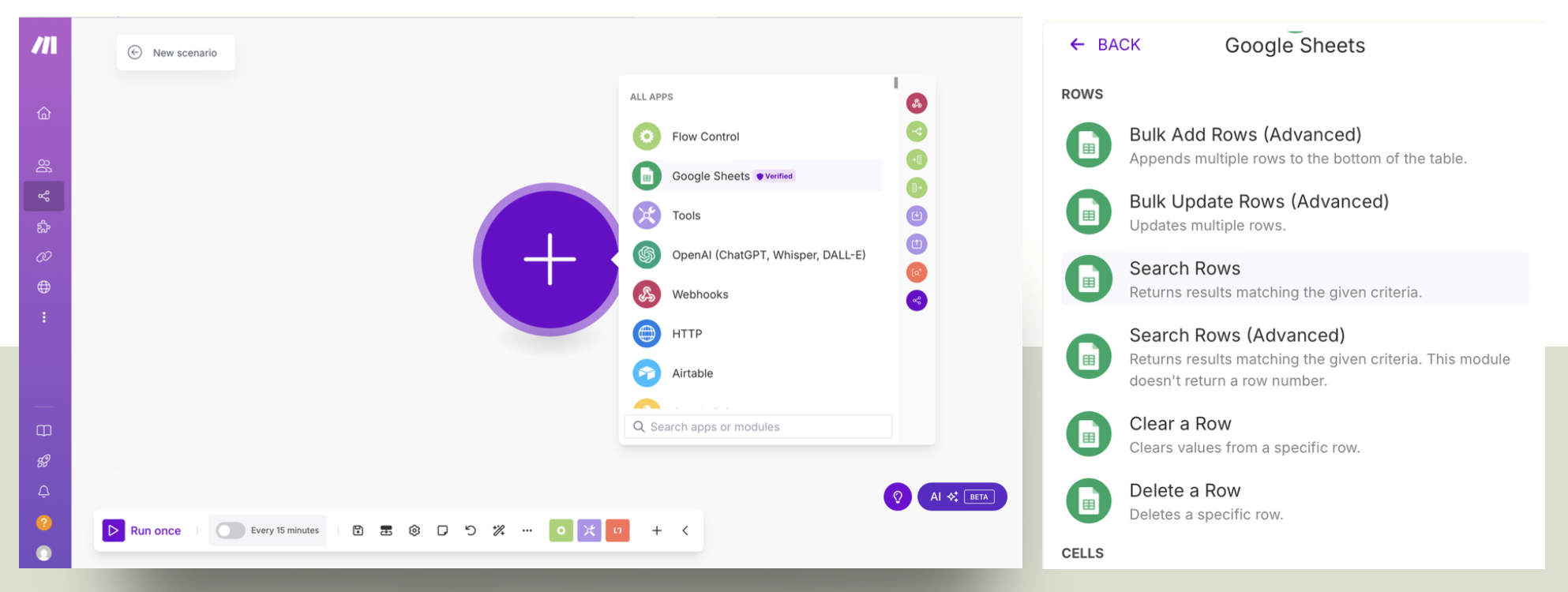
1. Veille et filtrage (Google Sheets + Make)
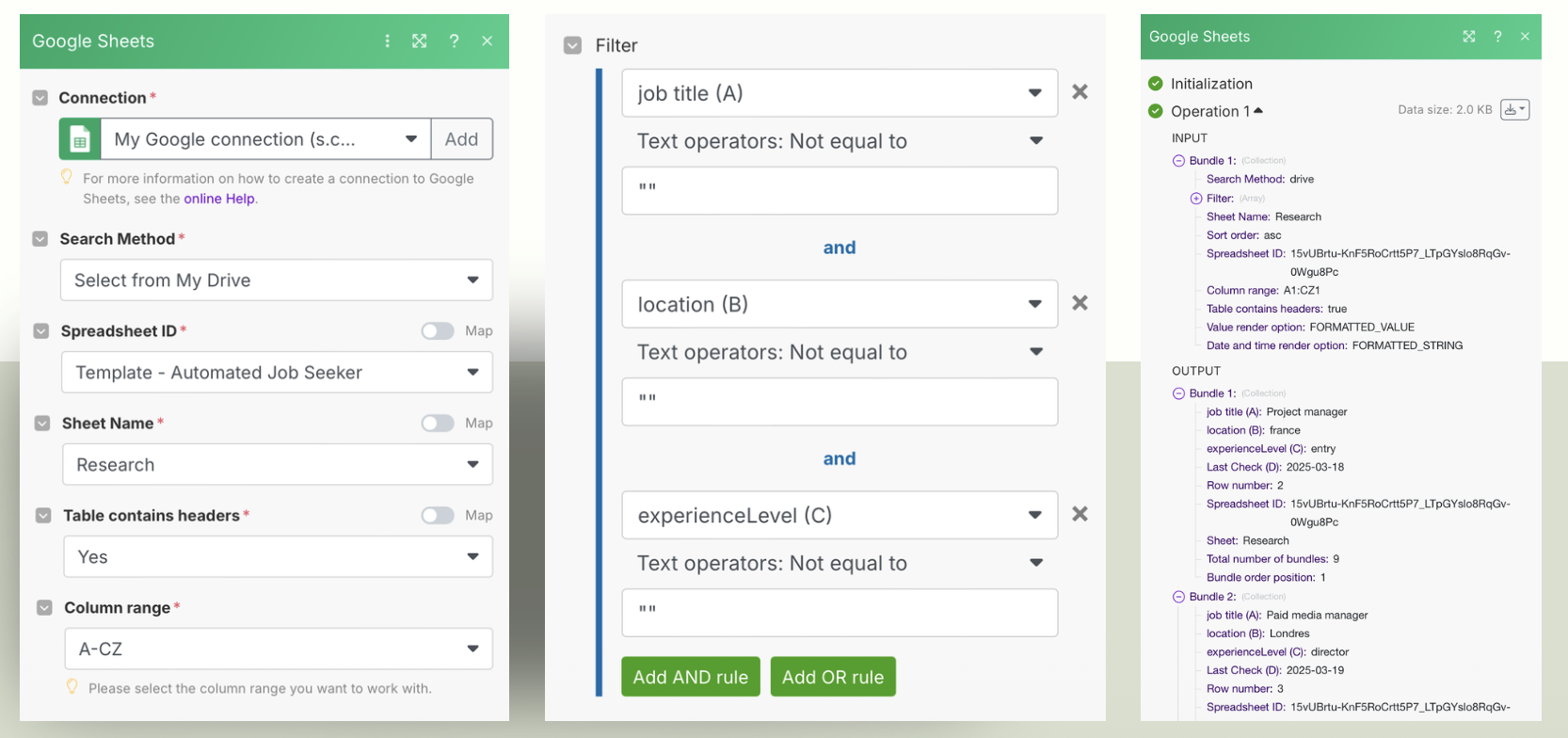
Google Sheets sert de point de contrôle : les critères de recherche (titre, localisation, experience) sont définis dans une feuille. Un scénario Make interroge cette feuille, récupère les critères et déclenche les étapes suivantes.
2. Collecte automatisée (Apify Actors)
Le scénario appelle l'acteur LinkedIn Job Scraper (Apify). Les offres correspondant aux filtres sont récupérées structurées (titre, entreprise, description, url). Les résultats sont poussés dans une feuille JobResult.
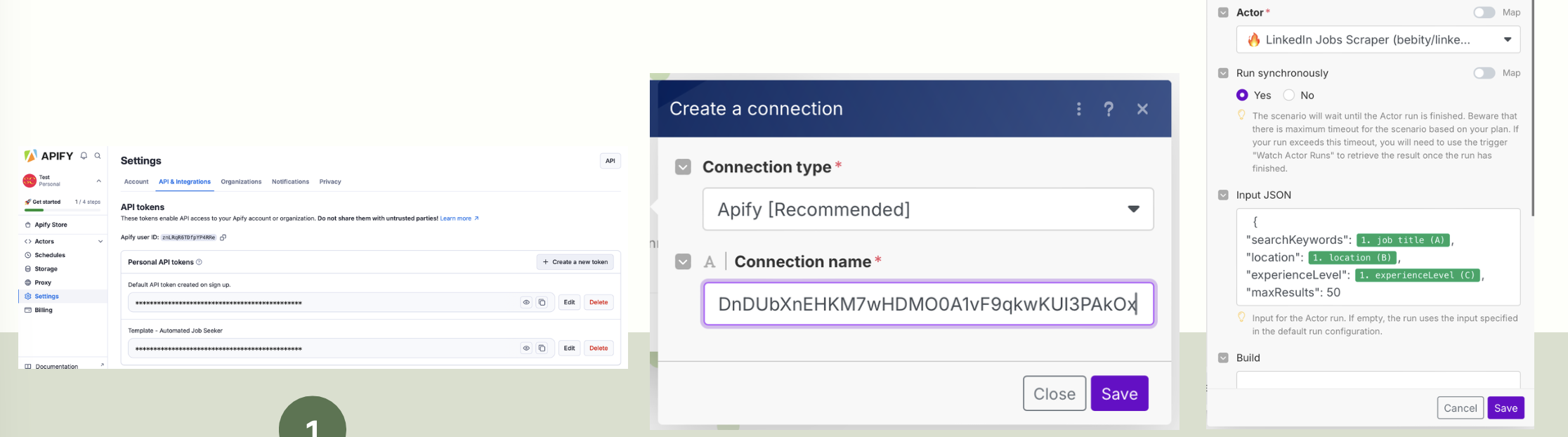
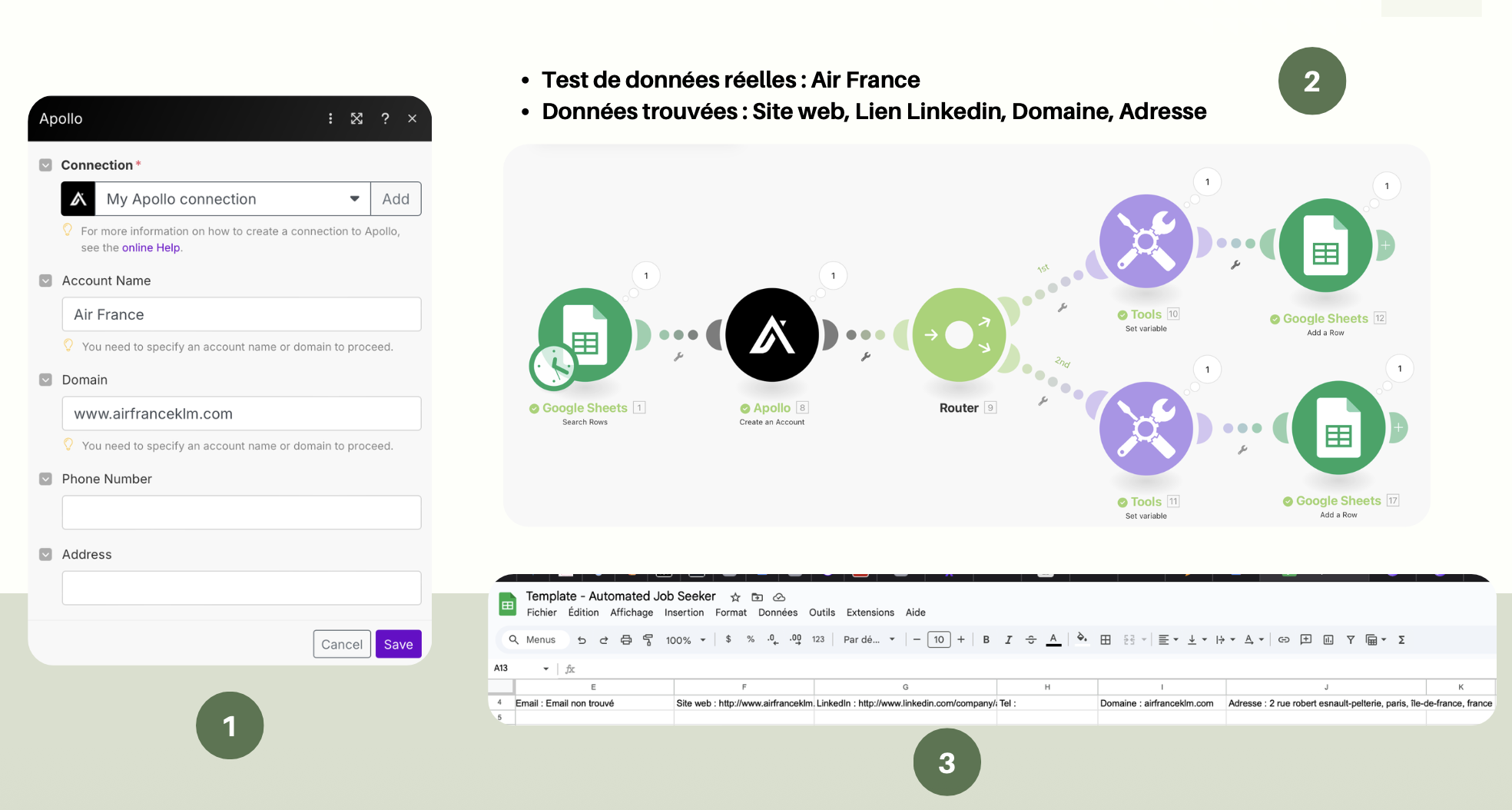
3. Enrichissement & validation (Apollo + Router)
Pour chaque entreprise ou offre sans contact, une requête Apollo tente de retrouver les coordonnées (email, téléphone, profil LinkedIn). Le Router Make permet de diriger les scénarios selon la disponibilité des données : enrichir, logger, ou marquer comme nécessitant une revue manuelle.
Dashboard de pilotage
Le suivi est assuré via Google Sheets :
- Volume d'offres collectées par jour
- Taux d'enrichissement des contacts
- Statut des entreprises (enrichi / à vérifier)
Ces métriques permettent de prioriser les actions et d'évaluer la performance du pipeline.
Résultats clés, insights & perspectives
- Réduction du temps consacré à la recherche et à la qualification des offres.
- Constitution d'une base structurée d'environ 60 prospects recruteurs qualifiés sur deux semaines de tests.
Perspectives d'amélioration :
- Lead Scoring : intégrer un score pour prioriser les opportunités selon fit (titre, expérience, localisation).
- Multichannel Nurturing : connecter la base à un outil d'emailing pour lancer des candidatures personnalisées.
- Enrichissement continu : compléter le pipeline par des modules de scraping supplémentaires (sites carrières, etc.).
Conclusion
Ce projet d'automatisation a permis de démontrer l'impact concret d’un pipeline no-code sur la productivité et la qualité des données en recrutement. En industrialisant la veille, la collecte et l’enrichissement, on peut se concentrer sur des tâches à plus forte valeur ajoutée, tout en disposant d’une base de prospects fiable et actualisée. Ce type d’approche est facilement transposable à d’autres cas d’usage pour des besoins RH (sourcing), commerciaux (prospection) ou productifs (veille marché).
Vous avez des questions ou souhaitez discuter ce projet ?
Projet réalisé en autonomie dans le cadre de la formation Lewagon & Audencia